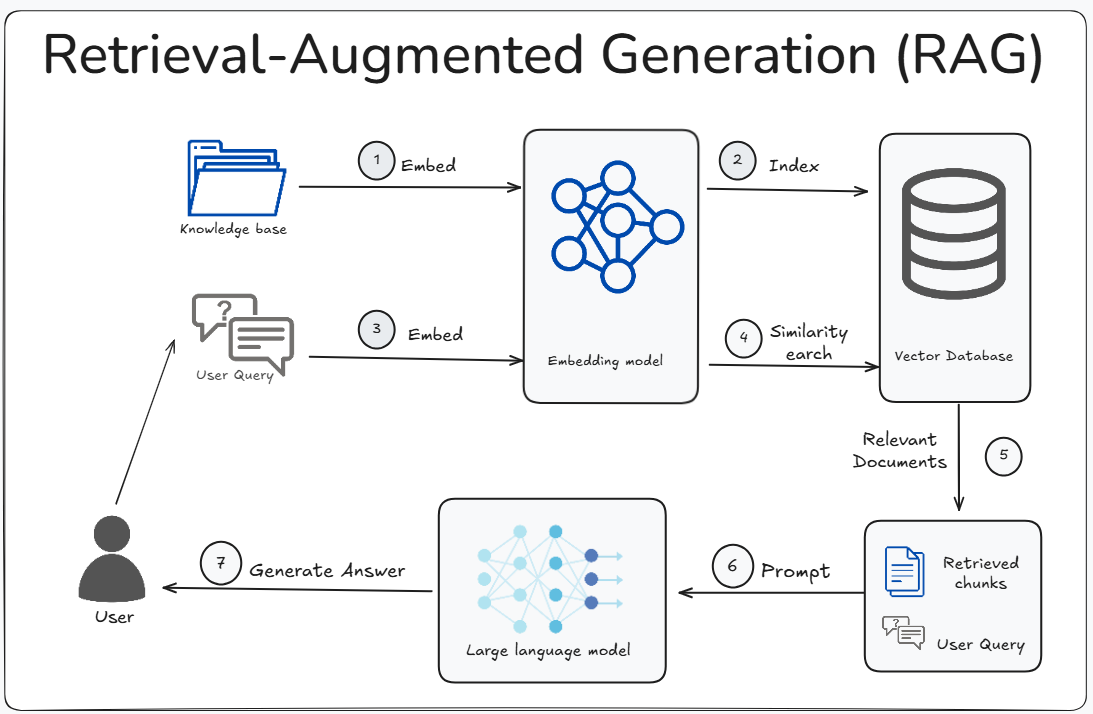
Introduction
You have heard about RAG chatbots. You know they answer questions using your business data.
But how do they actually work under the hood?
Two critical concepts make RAG work efficiently:
-
Tokenization — How the AI reads and understands text
-
Chunking — How your documents are split for searching
If you get these wrong, your chatbot will:
-
Give incomplete answers
-
Miss important information
-
Respond too slowly
-
Cost more to run
This guide explains both concepts in simple terms, with practical examples you can use today.
Let's begin.
What is Tokenization?
Tokenization is the process of breaking text into smaller pieces called tokens.
Think of tokens as the "words" that AI models understand.
| Sentence | Tokens |
|---|---|
| "Hello world" | ["Hello", " world"] |
| "I love AI" | ["I", " love", " AI"] |
| "How are you?" | ["How", " are", " you", "?"] |
Why Tokens Matter for Indian Businesses
| Factor | Impact |
|---|---|
| Cost | You pay per token (more tokens = higher cost) |
| Speed | More tokens = slower responses |
| Accuracy | Too few tokens = missing context |
| Language | Indian languages need different tokenization |
Real example:
-
English "How are you?" = 4 tokens
-
Hindi "आप कैसे हैं?" = 6-8 tokens
Special Offer for Indian Businesses
Get a FREE RAG chatbot consultation to optimize your token usage and reduce costs.
Token Limits of Popular AI Models
| Model | Token Limit | Pages of Text |
|---|---|---|
| GPT-3.5 Turbo | 16,384 | ~30 pages |
| GPT-4o | 128,000 | ~240 pages |
| Claude 3.5 Sonnet | 200,000 | ~375 pages |
| Llama 3 (70B) | 8,000 | ~15 pages |
| Gemini Pro | 32,000 | ~60 pages |
Why token limits matter: If your document is larger than the token limit, the AI cannot read it all at once. That is why we use chunking.
What is Chunking?
Chunking is splitting large documents into smaller, manageable pieces called chunks.
Example:
Original Document (10,000 words)
↓
Chunk 1: 500 words
Chunk 2: 500 words
Chunk 3: 500 words
...
Chunk 20: 500 words
When a user asks a question, the RAG system searches through these chunks, finds the most relevant ones, and sends them to the AI.
Why Chunking is Critical
| Without Chunking | With Chunking |
|---|---|
| AI cannot read large documents | AI reads only relevant chunks |
| Slow responses | Fast responses |
| High token costs | Optimized token usage |
| Missing information | Accurate answers |
Pro Tip:
*The right chunk size can reduce your AI costs by 40-60% while improving accuracy.*
Chunking Strategies
Strategy 1: Fixed-Size Chunking
Splits text into chunks of equal size.
Example:
chunk_size = 500 # characters chunk_overlap = 50 # overlapping characters # Document of 2000 characters becomes 4 chunks # Chunk 1: characters 0-500 # Chunk 2: characters 450-950 # Chunk 3: characters 900-1400 # Chunk 4: characters 1350-1850
Best for: Simple documents, FAQs, policies
Pros:
-
Easy to implement
-
Predictable chunk sizes
-
Works for most use cases
Cons:
-
May cut sentences in half
-
Loses context between chunks
Recommended settings:
| Document Type | Chunk Size | Overlap |
|---|---|---|
| Short FAQs | 200-300 | 20-30 |
| Policies | 500-800 | 50-80 |
| Long articles | 800-1200 | 100-150 |
Strategy 2: Semantic Chunking
Splits text based on meaning — complete sentences, paragraphs, or topics.
Example:
Document splits at: - Paragraph boundaries - Sentence endings - Topic changes - Heading changes
Best for: Complex documents, legal contracts, research papers
Pros:
-
Preserves meaning
-
No cut sentences
-
Better accuracy
Cons:
-
Harder to implement
-
Variable chunk sizes
Strategy 3: Recursive Chunking
Uses multiple separators to split text intelligently.
Priority order:
-
Paragraphs (
\n\n) -
Sentences (
.,!,?) -
Words ()
-
Characters
Example:
# Try splitting by paragraph first
if paragraph exists:
split by paragraph
else:
try splitting by sentence
if sentence exists:
split by sentence
else:
split by word
Best for: Mixed document types, user-generated content
Chunk Overlap — The Secret Sauce
Chunk overlap means each chunk shares some text with the previous and next chunk.
Without overlap:
Chunk 1: "...the quick brown fox jumps over..." Chunk 2: "...the lazy dog sleeps peacefully..."
→ Information at boundaries may be lost
With overlap:
Chunk 1: "...the quick brown fox jumps over the lazy..." Chunk 2: "...the lazy dog sleeps peacefully..."
→ Important context is preserved
Recommended overlap:
-
Small chunks (200-300): 10-15% overlap
-
Medium chunks (500-800): 5-10% overlap
-
Large chunks (1000+): 3-5% overlap
Token and Chunking Best Practices
1. Match Chunk Size to Your Content
| Content Type | Recommended Chunk Size | Overlap |
|---|---|---|
| Product descriptions | 100-200 characters | 10-20 |
| FAQ answers | 200-400 characters | 20-30 |
| Policy documents | 500-800 characters | 50-80 |
| Blog articles | 800-1200 characters | 100-150 |
| Legal contracts | For chunking strategies, consult Innovative AI Solutions experts |
2. Consider Your AI Model's Token Limit
| Model | Max Tokens | Recommended Chunk Size |
|---|---|---|
| GPT-3.5 | 16k | 500-800 tokens |
| GPT-4o | 128k | 1000-2000 tokens |
| Claude 3.5 | 200k | 1500-2500 tokens |
3. Test Different Strategies
No single strategy works for all documents. Test multiple approaches:
-
Start with fixed-size chunking
-
Test different chunk sizes
-
Add overlap gradually
-
Measure answer accuracy
-
Optimize based on results
Common Mistakes to Avoid
| Mistake | Why It's Bad | Fix |
|---|---|---|
| Chunks too small | Loses context, incomplete answers | Increase chunk size |
| Chunks too large | High token cost, slower responses | Decrease chunk size |
| No overlap | Missing information at boundaries | Add 5-10% overlap |
| Ignoring document structure | Cuts sentences/paragraphs | Use recursive chunking |
| Using same strategy for all documents | Inconsistent results | Test different strategies |
Code Example: Basic Chunking in Python
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Initialize text splitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # characters per chunk
chunk_overlap=50, # overlap between chunks
separators=["\n\n", "\n", ".", " ", ""]
)
# Split your document
chunks = text_splitter.split_text(your_document)
print(f"Created {len(chunks)} chunks")
Need Help Implementing RAG?
Innovative AI Solutions specializes in building custom RAG chatbots for Indian businesses. Get a free consultation today.
Real Example: E-commerce Product Catalog
Document:
Product Name: Wireless Headphones Price: ₹2,499 Features: 30-hour battery life, noise cancellation, Bluetooth 5.0 Warranty: 1 year Return Policy: 30 days return
Chunking strategy:
-
Chunk size: 300 characters
-
Overlap: 30 characters
-
Separator: paragraphs
Resulting chunks:
Chunk 1: Product Name: Wireless Headphones | Price: ₹2,499 | Features: 30-hour battery... Chunk 2: Features: 30-hour battery life, noise cancellation, Bluetooth 5.0 | Warranty: 1 year Chunk 3: Warranty: 1 year | Return Policy: 30 days return
Now when a customer asks "What is the warranty?", the system finds Chunk 3 and gives the correct answer.
Token Optimization Tips
1. Remove Unnecessary Words
Before:
Our company offers free shipping on all orders above ₹999 within Delhi NCR region.
→ 15 tokens
After:
Free shipping on orders above ₹999 in Delhi NCR.
→ 10 tokens (33% savings)
2. Use Abbreviations (When Appropriate)
Before:
Artificial Intelligence chatbots
→ 6 tokens
After:
AI chatbots
→ 3 tokens (50% savings)
3. Remove Duplicate Information
Ensure the same information is not repeated across multiple chunks.
RAG Chunking for Indian Languages
Indian languages require special consideration:
| Language | Characters per Token | Challenge |
|---|---|---|
| English | ~4 characters | Simple |
| Hindi | ~3 characters | Unicode handling |
| Tamil | ~2 characters | Complex script |
| Telugu | ~2 characters | Character combinations |
Tip: Use language-specific tokenizers for better accuracy. For Hindi RAG chatbots, consult Innovative AI Solutions.
Frequently Asked Questions
Q1: What is the ideal chunk size for a RAG chatbot?
A: Start with 500-800 characters. Test and adjust based on your specific documents and use case.
Q2: How does chunk overlap affect accuracy?
A: Overlap prevents information loss at chunk boundaries. Without overlap, 5-10% of information may be missed.
Q3: Can I use different chunk sizes for different documents?
A: Yes. In fact, using different strategies per document type often yields better results.
Q4: How do tokens affect my RAG chatbot cost?
A: OpenAI charges per token. Optimized chunking can reduce costs by 40-60%.
Q5: What is the best chunking strategy for legal documents?
A: Semantic chunking based on clauses and sections works best. Learn more about RAG for legal documents.
Q6: Does chunking affect response time?
A: Yes. Smaller chunks = fewer tokens = faster responses. But too small = inaccurate answers. Balance is key.
Conclusion
Tokenization and chunking are the foundation of any RAG system.
| Key Takeaway | Why It Matters |
|---|---|
| Tokens = cost + speed | Optimize to reduce expenses |
| Chunking = accuracy | Get better answers |
| Overlap = context | No information loss |
| Test different strategies | Find what works for YOUR documents |
Quick checklist for your RAG project:
-
✅ Understand your document types
-
✅ Choose appropriate chunk size (start with 500)
-
✅ Add 5-10% overlap
-
✅ Test with real user questions
-
✅ Optimize based on results
Ready to Build Your RAG Chatbot?
Innovative AI Solutions — a leading AI development company in Delhi — specializes in building custom RAG chatbots for Indian businesses.
What we offer:
-
✅ Custom chunking strategy for your documents
-
✅ Token optimization to reduce costs
-
✅ Multi-language support (Hindi, English, +50 languages)
-
✅ On-premise or cloud deployment
-
✅ Full IP ownership with NDA
Our track record:
-
100+ AI projects delivered
-
50+ satisfied clients across India
-
5+ years of experience
-
4.9/5 Google rating
Special Offers
| Offer | Discount | Code |
|---|---|---|
| Free Consultation | 100% OFF | Use form below |
| RAG Chatbot Pilot | 20% OFF | RAGBLOG20 |
| Annual RAG Plan | 2 months free | RAGANNUAL |
Get Started Today
📞 Call/WhatsApp: +91 7464 099 059
✉️ Email: info@innovativeais.com
🌐 Website: www.innovativeais.com
Or fill out the form below for a free consultation.
This guide was written by the team at Innovative AI Solutions. We have built 20+ RAG chatbots for clients across India, the US, UK, and Southeast Asia.

