The Big Question
"Abhishek, we have years of customer data – sales, support, behavior, everything. We know there are insights in there. But every time we try to analyze it, our systems crash. How do companies actually process big data without spending crores on hardware?"
This is the exact problem cloud computing was built to solve.
Here is the honest truth:
Big data processing is not about having the biggest server. It is about having the right architecture – one that scales, distributes work, and pays only for what you use.
The cloud makes this accessible to every business.
Let me show you how.
Step 3: The Big Data Problem (And How Cloud Solves It)
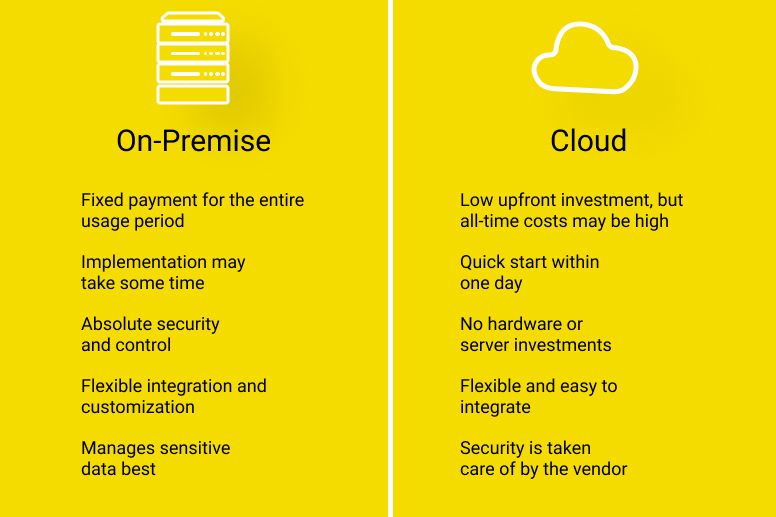
The Traditional Approach (On-Premise)
| Challenge | Traditional Solution | The Problem |
|---|---|---|
| Data volume growing | Buy larger servers | Expensive, still runs out |
| Processing takes too long | Buy more servers | Complex to manage, expensive |
| New types of data (JSON, images) | Buy specialized databases | Multiple systems, siloed data |
| Unpredictable processing needs | Buy for peak capacity | Idle hardware 90% of time |
| Need ML on large datasets | Buy GPU servers | ₹50 lakhs+ upfront |
The Cloud Approach
| Challenge | Cloud Solution | Why It Works |
|---|---|---|
| Data volume | Object storage (S3, Blob) | Scales to exabytes, pay per GB |
| Processing speed | Distributed computing (Spark, Hadoop) | 100s of servers, pay per hour |
| Multiple data types | Data lake (store raw, process later) | Store everything, schema on read |
| Unpredictable needs | Serverless + auto-scaling | Pay only for what you use |
| ML on large data | Managed ML + spot GPUs | Pay per training run, no upfront |
"The cloud turns big data from a capital expense into an operational expense. From 'can we afford the hardware?' to 'what insight is worth ₹500?'"
Step 4: The Cloud Data Analytics Stack
Here is how we architect data analytics in the cloud.
Architecture Overview
┌─────────────────────────────────────────────────────────────────┐
│ DATA SOURCES │
│ (Transactional DB, App Logs, IoT Sensors, User Events, Files) │
└───────────────────────────────┬─────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ DATA INGESTION │
│ (Kinesis, Pub/Sub, Event Hub, Kafka, Dataflow, Lambda) │
│ Real-time streaming or batch upload │
└───────────────────────────────┬─────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ DATA LAKE │
│ (S3, Azure Data Lake, Cloud Storage) │
│ Raw data – all formats, unlimited scale, low cost │
└───────────────────────────────┬─────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ DATA PROCESSING │
│ (EMR, Databricks, Synapse, Dataproc, Glue) │
│ Spark, Hadoop, Hive, Presto – transform, clean, enrich │
└───────────────────────────────┬─────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ DATA WAREHOUSE │
│ (Redshift, BigQuery, Synapse, Snowflake) │
│ Structured, optimized, ready for analysis │
└───────────────────────────────┬─────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ ANALYTICS & ML │
│ (SageMaker, Vertex AI, Databricks, QuickSight, Power BI) │
│ Dashboards, reports, predictions, insights │
└─────────────────────────────────────────────────────────────────┘
Why This Architecture Works
| Layer | Cloud Service Examples | Why in Cloud |
|---|---|---|
| Data Lake | S3, Azure Data Lake, GCS | Unlimited scale, ₹1-2/GB/month |
| Processing | EMR, Databricks, Synapse | 100s of servers, pay per hour |
| Warehouse | Redshift, BigQuery, Snowflake | Petabyte-scale, sub-second queries |
| ML | SageMaker, Vertex AI | Managed infrastructure, built-in algorithms |
Step 5: Key Cloud Services for Data Analytics
Here are the essential cloud services for each layer.
Data Storage (Data Lake)
| Provider | Service | Best For | Cost (approx) |
|---|---|---|---|
| AWS | S3 | All data types, unlimited | ₹1.6/GB/month |
| Azure | Data Lake Storage | Gen2 with hierarchical namespace | ₹1.5/GB/month |
| Cloud Storage | Multi-regional, strong consistency | ₹1.4/GB/month |
Why data lake in cloud:
-
No capacity planning – store as much as you want
-
Pay only for what you store
-
Multiple redundancy options (99.999999999% durability)
-
Lifecycle policies (move to cheaper cold storage after 30 days)
Data Processing (ETL)
| Provider | Service | Best For | Pricing Model |
|---|---|---|---|
| AWS | EMR (Elastic MapReduce) | Spark, Hadoop, Hive, Presto | Pay per EC2 hour |
| AWS | Glue (Serverless) | ETL, data catalog, Python/Spark | Pay per DPU hour |
| Azure | Synapse Analytics | Serverless or dedicated SQL/Spark | Pay per query or per node |
| Azure | Data Factory | ETL orchestration | Pay per activity |
| Dataproc | Managed Spark/Hadoop | Pay per node (preemptible 80% off) | |
| Dataflow (Serverless) | Stream and batch (Apache Beam) | Pay per CPU/memory hour | |
| Cross | Databricks | Spark + ML + SQL + Delta Lake | Pay per DBU (Databricks Unit) |
Cost comparison for 1-hour Spark job on 10 nodes:
| Provider | Approximate Cost |
|---|---|
| AWS EMR | ₹500-800 |
| Azure Synapse | ₹600-900 |
| Google Dataproc | ₹400-700 (with preemptible: ₹80-140) |
| Databricks | ₹800-1,200 |
"Serverless options (Glue, Dataflow) are simpler but often 2-3x more expensive for large, steady workloads. Choose wisely."
Data Warehousing
| Provider | Service | Best For | Pricing Model |
|---|---|---|---|
| AWS | Redshift | Petabyte-scale, columnar storage | Pay per node (RA3 instances) |
| AWS | Redshift Serverless | Variable workloads | Pay per RPU (Redshift Processing Unit) |
| Azure | Synapse Dedicated SQL Pool | Enterprise data warehouse | Pay per DWU (Data Warehouse Unit) |
| Azure | Synapse Serverless SQL | Query data lake directly | Pay per TB processed |
| BigQuery | Serverless, sub-second, massive scale | Pay per TB processed (or flat rate) | |
| Cross | Snowflake | Multi-cloud, separation of compute/storage | Pay per credit (compute) + storage |
Cost comparison for 1TB query per month:
| Provider | Approximate Monthly Cost |
|---|---|
| Redshift (dedicated, small) | ₹20,000-40,000 (fixed) |
| Redshift Serverless | ₹10,000-30,000 (variable) |
| Synapse Serverless | ₹12,000 (₹1,200 per TB processed) |
| BigQuery | ₹6,000-7,000 (₹500-600 per TB) |
| Snowflake | ₹15,000-30,000 (depends) |
"BigQuery is often the best price/performance for analytics queries – especially for one-time or ad-hoc analysis. But dedicated warehouses are cheaper for steady, 24/7 workloads."
Step 6: Real Examples – Data Analytics in the Cloud
Let me share three actual projects from our work.
Example 1: E-commerce – Customer Behavior Analytics
The client: An e-commerce brand with 10 million monthly visitors
The data: Clickstream logs (50GB/day), purchase history, product catalog, customer reviews
The challenge: Understand customer journey – what leads to purchase, where do they drop off, what products are frequently bought together
The cloud solution we built:
| Layer | Service | What We Did |
|---|---|---|
| Ingestion | Kinesis | Real-time clickstream from website |
| Data Lake | S3 | Raw logs stored for 30 days (1.5TB total) |
| Processing | Glue (ETL) | Hourly batches to clean, join, enrich |
| Data Warehouse | Redshift | Optimized tables for analysis |
| Analytics | QuickSight + Custom SQL | Dashboards for marketing, product teams |
The results:
-
Identified 3 major drop-off points in checkout (fixed = +15% conversion)
-
Discovered 5 product bundles with 2x+ purchase affinity (added to site = +8% AOV)
-
Customer segmentation: 12 segments personalized via email ( +20% email conversion)
Cost:
-
Monthly cloud bill: ₹1.2 lakhs (storage + processing + warehouse + BI)
-
ROI: 10x (from increased conversion and AOV alone)
Example 2: Fintech – Fraud Detection on Transaction Data
The client: A digital payments platform with 50 lakh+ monthly transactions
The data: Transaction logs, user profiles, device fingerprints, location data (~200GB/day)
The challenge: Detect fraud in real-time – need to score each transaction in under 100ms
The cloud solution we built:
| Layer | Service | What We Did |
|---|---|---|
| Ingestion | Kinesis (real-time) | Each transaction streamed immediately |
| Processing | Flink on EMR | Windowed aggregations (user velocity, etc.) |
| Features | SageMaker Feature Store | 200+ features pre-computed |
| ML Inference | SageMaker endpoint | <50ms response time |
| Data Lake | S3 | Historical data for training (3TB) |
| Training | SageMaker | XGBoost + deep learning models |
The results:
-
Fraud detection accuracy: 96% (up from 82% with rules)
-
Processing latency: <80ms per transaction
-
False positive rate: Reduced by 60%
-
Annual fraud savings: ₹2.5 crore
Cost:
-
Monthly cloud bill: ₹3.5 lakhs (compute + storage + ML)
-
ROI: 6x (from fraud reduction)
Example 3: Manufacturing – Predictive Maintenance IoT Analytics
The client: A factory with 500+ IoT sensors on critical equipment
The data: Vibration, temperature, current, pressure (50GB/day)
The challenge: Predict equipment failure 3-7 days in advance – requires time-series analysis and anomaly detection
The cloud solution we built:
| Layer | Service | What We Did |
|---|---|---|
| Ingestion | IoT Core | MQTT from sensors |
| Processing | Kinesis + Lambda | Real-time validation, anomaly detection |
| Storage | S3 + RDS | Raw data lake + time-series database (Timestream) |
| Analytics | Glue + Spark | Feature engineering on historical data |
| ML | SageMaker | LSTM (deep learning for time-series) |
| Monitoring | QuickSight + Alerts | Dashboard + SMS when failure predicted |
The results:
-
Failures predicted: 85% (3-7 days in advance)
-
Unplanned downtime: -70%
-
Maintenance costs: -35%
-
Equipment lifespan: +20%
Cost:
-
Monthly cloud bill: ₹1.5 lakhs
-
Savings: ₹2 crore/year (downtime + maintenance)
*"Without cloud, this project would have required ₹50 lakhs+ upfront for hardware. Cloud made it possible to start with a small pilot and scale."*
Step 7: Big Data Processing Patterns in Cloud
Here are the most common patterns we use.
Pattern 1: Batch Processing
When to use: Scheduled analysis, nightly ETL, historical reporting
How it works:
Raw Data (S3) → Spark Job (EMR) → Clean Data (S3) → Redshift → Dashboard
Best for: Daily sales reports, customer segmentation, inventory analysis
Typical cost per run (10GB data): ₹50-200
Pattern 2: Real-Time Streaming
When to use: Fraud detection, live dashboards, personalization
How it works:
Event Stream (Kinesis) → Stream Processor (Flink) → Action (API call, alert, DB)
Best for: Real-time fraud detection, live user recommendations, system monitoring
Typical cost per hour (1,000 events/sec): ₹100-500
Pattern 3: Interactive Queries
When to use: Ad-hoc analysis, data exploration, BI dashboards
How it works:
Data Warehouse (BigQuery/Redshift) → SQL Query → Results (<5 seconds)
Best for: Data analysts exploring trends, executives checking KPIs
Typical cost per query (1TB scanned): ₹500-1,200 (BigQuery cheapest)
Pattern 4: Machine Learning Pipelines
When to use: Model training, feature engineering, batch predictions
How it works:
Clean Data → Feature Store → Model Training → Model Registry → Batch/Real-time Inference
Best for: Recommendation engines, fraud detection, predictive maintenance
Typical cost per training (10GB data, 1 hour GPU): ₹200-500
Step 8: Cost Optimization for Big Data in Cloud
Big data can get expensive if not optimized. Here is how to control costs.
Strategy 1: Use Data Lifecycle Policies
| Data Age | Storage Tier | Cost per GB |
|---|---|---|
| 0-30 days | Hot (S3 Standard) | ₹1.60 |
| 30-90 days | Warm (S3 Infrequent Access) | ₹1.00 |
| 90-365 days | Cold (S3 Glacier) | ₹0.30 |
| 365+ days | Archive (Glacier Deep) | ₹0.10 |
Savings: 90%+ on old data
Strategy 2: Use Preemptible/Spot Instances for Processing
| Workload Type | Use Spot? | Savings |
|---|---|---|
| Batch ETL (can retry) | Yes | 70-90% |
| Training ML models (checkpoints) | Yes | 70-90% |
| Real-time streaming | No | – |
| Interactive queries | No | – |
Strategy 3: Partition and Cluster Your Data
Bad approach: One big file. Query scans everything = expensive.
Good approach: Partition by date. Query scans only relevant partitions = cheaper.
| Query | Without Partition | With Partition |
|---|---|---|
| "Today's sales" | Scans 1TB | Scans 10GB (₹1,200 → ₹12) |
Strategy 4: Use Columnar Storage Formats
| Format | Best For | Why |
|---|---|---|
| Parquet | Analytics queries | Columnar = scan only needed columns |
| ORC | Hive/Spark workloads | Similar to Parquet |
| Avro | Serialization | Row-based, good for writes |
| JSON | Debugging, small files | Human-readable, inefficient |
Switch from CSV to Parquet: 90% smaller, 5-10x faster queries
Strategy 5: Set Up Budget Alerts
| Alert Level | Action |
|---|---|
| 50% of budget | Notification – check usage |
| 80% of budget | Notification + review queries |
| 100% of budget | Notification + auto-pause non-critical jobs |
"The most expensive query is the one you forgot you left running."
Step 9: Cloud Provider Comparison for Data Analytics
Here is how the three major clouds compare.
| Capability | AWS | Azure | Google Cloud |
|---|---|---|---|
| Data Lake | S3 (most mature) | Data Lake Gen2 | Cloud Storage |
| Serverless SQL | Athena (over S3) | Synapse Serverless | BigQuery (best in class) |
| Managed Spark | EMR | Synapse + Databricks | Dataproc |
| Streaming | Kinesis (mature) | Event Hub | Pub/Sub + Dataflow |
| Data Warehouse | Redshift | Synapse | BigQuery (best price/performance) |
| ML Platform | SageMaker (richest) | Azure ML | Vertex AI |
| Orchestration | Glue Workflows + MWAA | Data Factory | Cloud Composer (Airflow) |
| Best for | Broadest services | Microsoft shops | Analytics-first, BigQuery |
Step 10: Getting Started – A Practical Roadmap
Here is how to start your cloud data analytics journey.
Phase 1: Data Lake (Week 1-2)
-
Set up cloud storage (S3/Blob/GCS)
-
Ingest existing data (CSV, JSON, logs)
-
Query with serverless SQL (Athena, BigQuery)
Cost: ₹5,000-10,000/month
Phase 2: Automated ETL (Week 3-6)
-
Build pipelines to clean and transform data
-
Schedule daily processing (Glue/Dataflow/Data Factory)
-
Move processed data to warehouse
Cost: ₹20,000-50,000/month
Phase 3: Analytics & BI (Week 6-8)
-
Set up BI dashboard (QuickSight/Power BI/Looker)
-
Create key dashboards (sales, customers, operations)
-
Train team on self-service analytics
Cost: ₹10,000-30,000/month (BI tools)
Phase 4: Advanced Analytics & ML (Week 8-12)
-
Build a simple ML model (prophet for forecasting)
-
Deploy batch predictions
-
Integrate predictions into applications
Cost: Variable (pay per training + inference)
Step 11: Frequently Asked Questions
Q1: How much data can the cloud handle?
Essentially unlimited. The largest cloud data lakes are petabytes (1,000+ TB). For reference, all the text ever written is ~50PB.
Q2: Is cloud data analytics expensive?
For occasional queries, it is very cheap (₹5-50 per query). For 24/7 heavy processing, it can be expensive – but still often cheaper than on-premise hardware + staff.
Q3: Which cloud is best for data analytics?
-
Google Cloud (BigQuery) for serverless analytics at scale
-
AWS for broadest services and most mature tools
-
Azure for Microsoft shops and enterprise integration
Q4: Do I need a data warehouse if I have a data lake?
Yes. Data lake is for raw data (cheap storage). Data warehouse is for structured, optimized data (fast queries). Most organizations need both.
Q5: What is a data lakehouse?
A newer architecture that combines data lake (cheap storage) with data warehouse (fast queries) – using formats like Delta Lake, Iceberg, Hudi. Databricks and Snowflake are popular.
Q6: How fast is querying on the cloud?
-
BigQuery: Sub-second on terabytes (serverless)
-
Redshift: Seconds on petabytes (dedicated)
-
Athena: 1-30 seconds on terabytes (serverless over S3)
Q7: Can I process streaming data in real-time?
Yes. Kinesis, Pub/Sub, Event Hub, Kafka handle millions of events per second. Sub-second latency is possible.
Q8: How do I secure my data in the cloud?
Encryption at rest and in transit. Access controls (IAM, VPC). Network isolation. Audit logging. Use cloud-native security tools (Macie, GuardDuty, Security Command Center).
Q9: What is the smallest budget data analytics project?
₹10,000-20,000/month – small data lake (10GB) with Athena for queries and QuickSight dashboards.
Q10: Why choose Innovative AI Solutions for data analytics?
Because we have built data pipelines for healthcare, fintech, manufacturing, and e-commerce. Because we know how to optimize for cost and performance. Because we are based in Delhi – you can visit our team. And because 80% of our clients return for more.
Step 12: Final Tagline (SEO & Social Media Friendly)
"Data is the new oil. The cloud is the refinery. Here is how to process big data, run analytics, and get insights – without building your own data center."
Short version for LinkedIn/Twitter:
Big data analytics used to require ₹50 lakhs+ in hardware. The cloud made it accessible to every business. Here is how to build your data pipeline.
Hashtags:
#BigData #DataAnalytics #DataScience #CloudComputing #AWS #Azure #GoogleCloud #DataEngineering #InnovativeAISolutions
Ready to Unlock Insights from Your Data?
You are sitting on a goldmine of data. Let us help you extract the insights – without spending crores on hardware.
Contact Us
Phone:
+91 7464 099 059
+91 96899 67356
Email:
info@innovativeais.com
Office Address:
Netaji Subhash Place, Pitampura, Delhi – 110034
Working Hours:
Monday–Friday, 10:00 AM – 7:00 PM IST