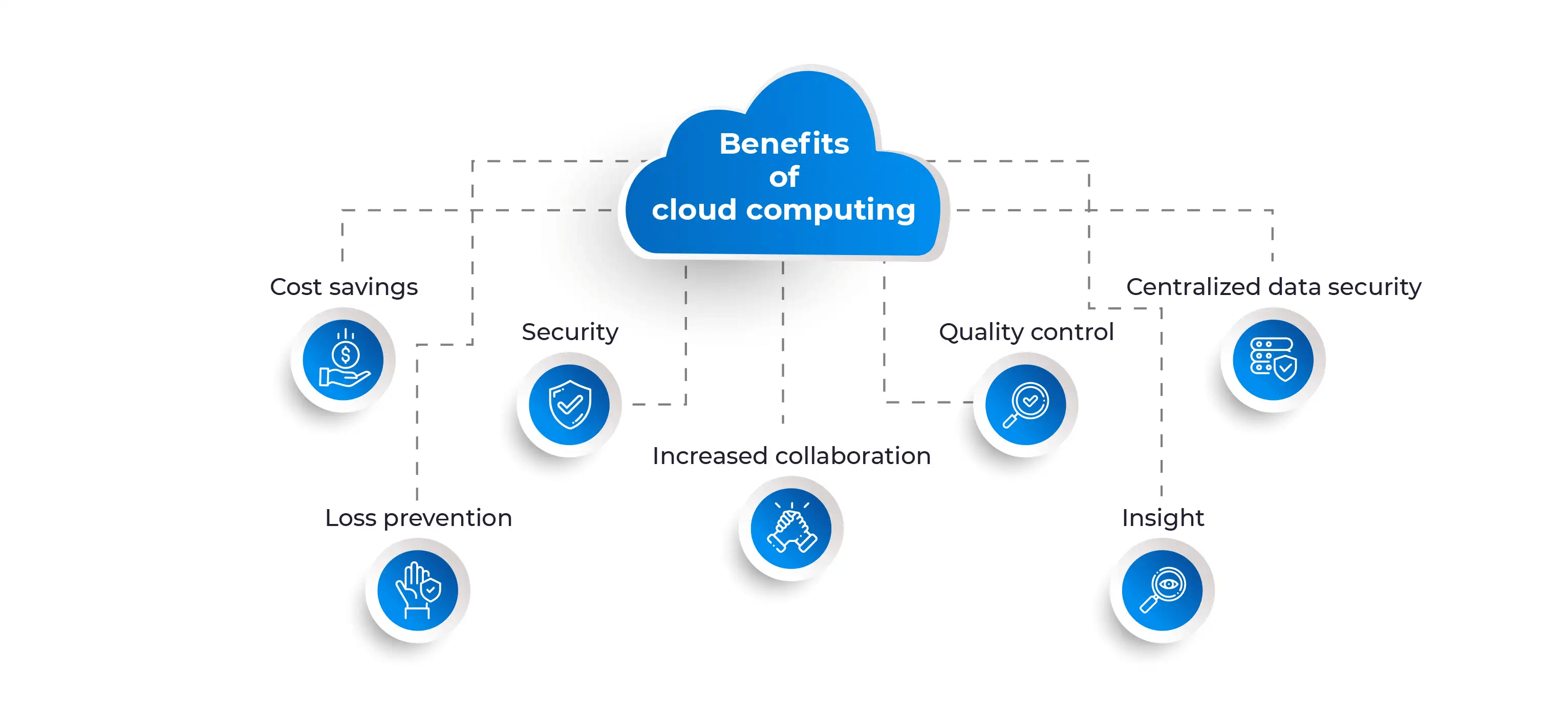
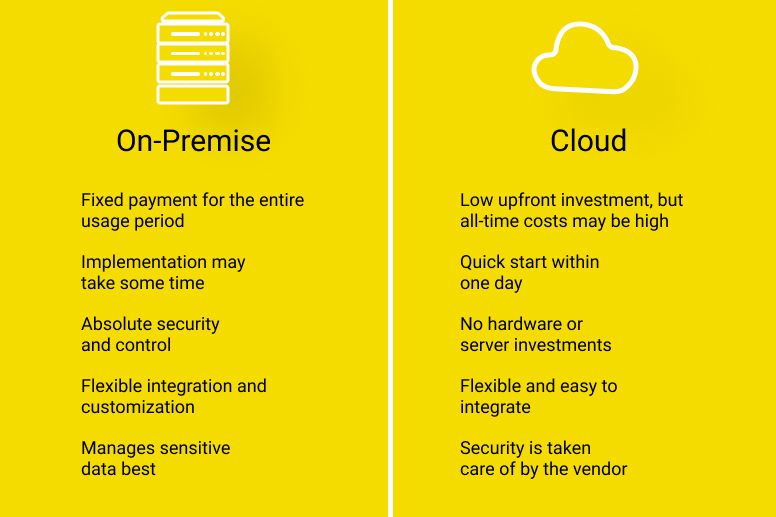
Why AI Is Hard to Scale
AI workloads have characteristics that make scaling challenging.
| Characteristic | Why It Is Hard | Cloud Solution |
|---|---|---|
| Compute intensity | Models require significant processing power, especially for training and complex inference | Elastic GPU and TPU clusters that scale up and down on demand |
| Spiky traffic patterns | Inference demand can spike unpredictably, requiring capacity without overprovisioning | Auto-scaling infrastructure that adds resources during peaks and removes them during lulls |
| Data intensity | Models need access to large datasets, often across multiple storage systems | Unified data lakehouses with high-throughput access to training and inference data |
| Statefulness | Conversations, sessions, and batch jobs require state persistence across requests | Distributed storage and caching services that maintain state at scale |
| Version complexity | Models are updated frequently, requiring careful version management and rollback | Container registries, model registries, and deployment pipelines that manage versioning |
| Cost sensitivity | AI infrastructure can be expensive, especially at scale | Pay-per-use pricing, spot instances, and cost optimization tools |
The challenge is not that scaling is impossible. It is that scaling requires infrastructure that most organizations cannot build for themselves. The cloud provides this infrastructure as a service, making scalable AI accessible to any organization with a credit card.
Step 3: Cloud Services for Scalable AI
Compute Services
| Service | Purpose | How It Enables Scaling |
|---|---|---|
| GPU instances | Training and inference for deep learning models | Scale from one GPU to thousands on demand |
| TPU instances | Accelerated training for TensorFlow models | Higher throughput per dollar for supported workloads |
| Serverless functions | Event-driven inference for low-volume or spiky workloads | Scale to zero when idle; scale to thousands of concurrent executions when busy |
| Container orchestration | Deploy and manage model containers at scale | Auto-scaling, load balancing, and self-healing for inference endpoints |
| Batch processing | Large-scale offline inference and training jobs | Distribute work across thousands of cores with automatic retry and failure handling |
Storage Services
| Service | Purpose | How It Enables Scaling |
|---|---|---|
| Object storage | Store training data, model artifacts, and inference results | Unlimited capacity, pay only for what you use |
| Data lakes | Store raw data in native formats for AI training | Petabyte-scale storage with high-throughput access |
| Vector databases | Store embeddings for semantic search and RAG | Index billions of vectors with low-latency similarity search |
| Caching | Store frequent inference results to reduce compute costs | In-memory access with automatic expiration and eviction |
| Distributed file systems | High-throughput access for distributed training | Parallel access from thousands of training workers |
Data Processing Services
| Service | Purpose | How It Enables Scaling |
|---|---|---|
| Stream processing | Real-time inference on streaming data | Process millions of events per second with sub-second latency |
| Batch processing | Large-scale data preparation and transformation | Distribute work across thousands of cores; scale to petabytes |
| Workflow orchestration | Coordinate multi-step AI pipelines | Manage dependencies, retries, and error handling at scale |
Model Serving Services
| Service | Purpose | How It Enables Scaling |
|---|---|---|
| Managed model serving | Deploy models as scalable APIs | Auto-scaling, load balancing, and version management without infrastructure management |
| Serverless inference | Pay-per-inference model hosting | Scale to zero when idle; no cold starts with provisioned concurrency |
| Multi-model serving | Host multiple models on shared infrastructure | Share GPU resources across models, reducing cost |
| Model monitoring | Track performance, drift, and resource usage | Alert on anomalies, trigger retraining, optimize resource allocation |
Step 4: Architectural Patterns for Scalable AI
Pattern 1: Stateless Inference with Auto-Scaling
The simplest scalable pattern treats inference as stateless. Each request is independent. The system does not remember previous requests. This allows the inference service to scale horizontally: add more instances when traffic increases, remove instances when traffic decreases.
| Component | Scaling Behavior |
|---|---|
| Load balancer | Distributes requests across healthy instances |
| Auto-scaling group | Adds or removes instances based on CPU utilization or request queue depth |
| Instance | Runs model inference on one request at a time |
| Cache | Stores frequent results to reduce load on inference instances |
This pattern works for request-response use cases where each request is independent: image classification, sentiment analysis, translation, and content moderation.
Pattern 2: Stateful Inference with Session Management
When inference requires conversation memory or user context, the system must manage state across requests. Stateless scaling becomes more complex.
| Component | Scaling Behavior |
|---|---|
| Session store | Redis or DynamoDB stores conversation state; scales independently of inference instances |
| Inference instance | Retrieves session state, processes request, updates session state |
| Load balancer | Routes requests from the same session to the same instance when possible (session affinity) |
| Auto-scaling | Scales inference instances based on load; session state persists even when instances are replaced |
This pattern works for chatbots, personalization, and any application where context matters across requests.
Pattern 3: Asynchronous Batch Processing
When inference is not time-sensitive, batch processing is more cost-effective than real-time. The system queues requests, processes them in batches, and stores results for later retrieval.
| Component | Scaling Behavior |
|---|---|
| Queue | Accepts requests at variable rate; decouples producers from consumers |
| Batch processor | Reads batches of requests, processes them together on GPU, writes results |
| Result store | Stores inference results for later retrieval |
| Auto-scaling | Scales batch processors based on queue depth; can use spot instances for lower cost |
This pattern works for document processing, video analysis, and any workload where results are not needed immediately.
Pattern 4: Multi-Model Routing
When different types of requests require different models, the system routes each request to the appropriate model. Different models may have different scaling requirements.
| Component | Scaling Behavior |
|---|---|
| Router | Classifies request type, routes to appropriate model endpoint |
| Model endpoint (small) | Low-latency, high-volume models; scales for large traffic |
| Model endpoint (large) | High-accuracy, lower-volume models; scales independently |
| Cache | Stores routing decisions to avoid repeated classification |
This pattern works for applications with diverse request types where accuracy requirements vary by request.
Step 5: Real-World Scaling Examples
Example: E-commerce Recommendation Engine at Scale
| Metric | Scale | Cloud Solution |
|---|---|---|
| Catalog size | 10 million products | Vector database indexes product embeddings; shards across multiple nodes |
| User count | 50 million active users | Session state stored in distributed cache; user embeddings retrieved on demand |
| Request rate | 100,000 per second | Load balancer distributes traffic; auto-scaling inference endpoints |
| Peak load | 500,000 per second (holiday shopping) | Elastic scaling adds capacity within minutes |
| Latency requirement | Under 50 milliseconds | Caching for popular items; optimized inference for cold items |
The system scales automatically from weekday lows to holiday peaks without human intervention. The cost during peaks is higher, but the revenue during peaks more than offsets the additional infrastructure spend.
Example: Document Processing Pipeline at Scale
| Metric | Scale | Cloud Solution |
|---|---|---|
| Document volume | 10 million per day | Queue accepts documents at variable rate; decouples upload from processing |
| Processing time per document | 5 seconds | Batch processors run on GPU instances; thousands of concurrent processors |
| Peak volume | 50 million per day (tax season) | Auto-scaling adds processors based on queue depth |
| Cost optimization | Use spot instances for 80 percent of capacity | 60 to 70 percent lower cost than on-demand |
| Results retrieval | Sub-second access to processed results | Results stored in key-value store with automatic expiration |
The system processes documents in batches, scaling to handle seasonal peaks and scaling down to near-zero during low-volume periods. The use of spot instances reduces cost significantly without impacting throughput, as the batch process can tolerate interruptions.
Step 6: Cost Optimization at Scale
| Strategy | How It Works | Typical Savings |
|---|---|---|
| Spot instances | Use spare capacity for batch processing at 60 to 90 percent discount | 60 to 70 percent for fault-tolerant workloads |
| Reserved instances | Commit to 1- or 3-year usage for steady-state workloads | 40 to 60 percent compared to on-demand |
| Auto-scaling | Right-size capacity to match demand; no idle resources | 30 to 50 percent compared to overprovisioned fixed capacity |
| Caching | Store frequent inference results; avoid recomputation | 50 to 80 percent reduction in inference cost for cacheable workloads |
| Model quantization | Reduce model precision from FP32 to INT8 | 4 times memory reduction, 2 to 3 times speedup, minimal accuracy loss |
| Batch processing | Process multiple requests together on GPU | 2 to 5 times throughput per GPU hour |
The most successful scalable AI deployments use a combination of these strategies, applying each where it makes sense. Batch inference runs on spot instances. Steady-state production traffic runs on reserved instances. Spiky traffic runs on on-demand with auto-scaling. Caching eliminates redundant computation. Quantization reduces memory and compute requirements.
Step 7: Implementation Roadmap
Phase 1: Foundation (Months 1 to 2)
| Action | Output |
|---|---|
| Containerize model inference | Portable, scalable deployment unit |
| Set up model registry | Versioned storage for model artifacts |
| Implement basic load testing | Baseline performance metrics |
| Configure cloud monitoring | Visibility into resource utilization |
Phase 2: Scaling (Months 2 to 4)
| Action | Output |
|---|---|
| Implement auto-scaling for inference endpoints | Capacity that matches demand |
| Set up multi-region deployment | Low latency for global users |
| Implement caching for frequent requests | Reduced inference cost |
| Add session management for stateful workloads | Scale without losing context |
Phase 3: Optimization (Months 4 to 6)
| Action | Output |
|---|---|
| Implement model quantization | Lower memory and compute requirements |
| Configure spot instances for batch processing | Lower cost for fault-tolerant workloads |
| Set up cost monitoring and alerts | No surprise bills |
| Optimize scaling thresholds | Balance cost and performance |
Phase 4: Continuous Improvement (Ongoing)
| Action | Output |
|---|---|
| Monitor model performance in production | Detect drift and degradation |
| Analyze cost trends | Identify optimization opportunities |
| Review scaling events | Tune thresholds and capacity |
| Update models without downtime | Continuous improvement |
Step 8: Common Scaling Mistakes
| Mistake | Why It Fails | The Fix |
|---|---|---|
| Premature optimization | Build complex scaling before proving value | Start with simple, scalable architecture; optimize when needed |
| Ignoring state | Session state lost when instances scale | Use external session store |
| No load testing | Discover scaling limits during incidents | Test before production |
| Over-provisioning | Pay for idle capacity | Auto-scale to match demand |
| Under-provisioning | Performance degradation under load | Set appropriate scaling thresholds and buffer capacity |
| Single region | High latency for global users | Deploy to multiple regions |
| No fallback | Single point of failure | Design for graceful degradation |
Step 9: Frequently Asked Questions
Q1: How many users can a cloud-based AI solution handle?
The limit is not the cloud. It is your budget and architecture. Cloud services scale to millions of concurrent users, but the cost scales with usage. Design for your expected peak, and let auto-scaling handle spikes beyond that.
Q2: Is serverless inference suitable for production?
Yes, for workloads that tolerate cold start latency. Serverless functions scale to zero when idle, which is cost-effective for low-volume or spiky traffic. For steady, high-volume traffic, provisioned concurrency or dedicated instances may be more cost-effective.
Q3: How do I choose between GPU, TPU, and CPU for inference?
CPU is cheapest but slowest. GPU is faster and cost-effective for batch processing. TPU is fastest for TensorFlow models but requires code changes. Use CPU for low-volume inference, GPU for medium-volume or batch, and TPU for high-volume TensorFlow workloads.
Q4: How do I keep costs predictable when scaling?
Set budget alerts at multiple thresholds. Use reserved instances for baseline capacity. Use on-demand for spikes. Use spot for batch processing. Monitor cost per inference and set alerting when it exceeds thresholds.
Q5: What is the most scalable architecture for a chatbot?
Stateless retrieval-augmented generation (RAG) with an external vector database scales better than fine-tuned models with long context windows. The retrieval layer scales independently of the generation layer. The generation layer is stateless, enabling horizontal scaling.
Q6: How do I update a model without downtime?
Use blue-green deployment: deploy the new model alongside the old, test it, then switch traffic gradually. Canary deployment: send a small percentage of traffic to the new model, monitor for errors, then increase the percentage. Both patterns require the ability to route traffic to different model versions.
Q7: How can Innovative AI Solutions help?
We help businesses design, build, and scale AI solutions on cloud, from architecture selection and implementation to cost optimization and ongoing management.
Step 10: Final Tagline
Scaling AI is hard, but cloud technology makes it possible. The same infrastructure that serves one request per second can serve one million with the right architecture. The key is designing for scale from the start: stateless services, external state management, auto-scaling, and cost optimization. Organizations that master these patterns will outrun competitors who are still struggling to move beyond prototypes.
Short version: Scalable AI solutions using cloud technology – why AI is hard to scale, cloud services that enable scaling, architectural patterns, real-world examples, cost optimization, and implementation roadmap.
Hashtags: #ScalableAI #CloudAI #AIInfrastructure #AIScaling #ServerlessAI #GPUScaling #AICostOptimization #InnovativeAISolutions
Contact Us
Phone: +91 7464 099 059 / +91 96899 67356
Email: info@innovativeais.com
Address: Netaji Subhash Place, Pitampura, Delhi – 110034
Website: https://innovativeais.com
About the Author
Abhishek Kumar
Founder & CEO, Innovative AI Solutions
5+ years building scalable AI solutions on cloud. Based in Delhi, serving clients across India.